Chapter 10 CBP, wild-type versus knock-out
10.1 Background
Here, we perform a window-based DB analysis to identify differentially bound (DB) regions for CREB-binding protein (CBP). This particular dataset comes from a study comparing wild-type (WT) and CBP knock-out (KO) animals (Kasper et al. 2014), with two biological replicates for each genotype. As before, we obtain the BAM files and indices from chipseqDBData.
## DataFrame with 4 rows and 3 columns
## Name Description Path
## <character> <character> <List>
## 1 SRR1145787 CBP wild-type (1) <BamFile>
## 2 SRR1145788 CBP wild-type (2) <BamFile>
## 3 SRR1145789 CBP knock-out (1) <BamFile>
## 4 SRR1145790 CBP knock-out (2) <BamFile>10.2 Pre-processing
We check some mapping statistics for the CBP dataset with Rsamtools, as previously described.
library(Rsamtools)
diagnostics <- list()
for (b in seq_along(cbpdata$Path)) {
bam <- cbpdata$Path[[b]]
total <- countBam(bam)$records
mapped <- countBam(bam, param=ScanBamParam(
flag=scanBamFlag(isUnmapped=FALSE)))$records
marked <- countBam(bam, param=ScanBamParam(
flag=scanBamFlag(isUnmapped=FALSE, isDuplicate=TRUE)))$records
diagnostics[[b]] <- c(Total=total, Mapped=mapped, Marked=marked)
}
diag.stats <- data.frame(do.call(rbind, diagnostics))
rownames(diag.stats) <- cbpdata$Name
diag.stats$Prop.mapped <- diag.stats$Mapped/diag.stats$Total*100
diag.stats$Prop.marked <- diag.stats$Marked/diag.stats$Mapped*100
diag.stats## Total Mapped Marked Prop.mapped Prop.marked
## SRR1145787 28525952 24289396 2022868 85.15 8.328
## SRR1145788 25514465 21604007 1939224 84.67 8.976
## SRR1145789 34476967 29195883 2412650 84.68 8.264
## SRR1145790 32624587 27348488 2617879 83.83 9.572We construct a readParam object to standardize the parameter settings in this analysis.
The ENCODE blacklist is again used to remove reads in problematic regions (Consortium 2012).
library(BiocFileCache)
bfc <- BiocFileCache("local", ask=FALSE)
black.path <- bfcrpath(bfc, file.path("https://www.encodeproject.org",
"files/ENCFF547MET/@@download/ENCFF547MET.bed.gz"))
library(rtracklayer)
blacklist <- import(black.path)We set the minimum mapping quality score to 10 to remove poorly or non-uniquely aligned reads.
## Extracting reads in single-end mode
## Duplicate removal is turned off
## Minimum allowed mapping score is 10
## Reads are extracted from both strands
## No restrictions are placed on read extraction
## Reads in 164 regions will be discarded10.3 Quantifying coverage
10.3.1 Computing the average fragment length
The average fragment length is estimated by maximizing the cross-correlation function (Figure 10.1), as previously described. Generally, cross-correlations for TF datasets are sharper than for histone marks as the TFs typically contact a smaller genomic interval. This results in more pronounced strand bimodality in the binding profile.
x <- correlateReads(cbpdata$Path, param=reform(param, dedup=TRUE))
frag.len <- maximizeCcf(x)
frag.len## [1] 161plot(1:length(x)-1, x, xlab="Delay (bp)", ylab="CCF", type="l")
abline(v=frag.len, col="red")
text(x=frag.len, y=min(x), paste(frag.len, "bp"), pos=4, col="red")
Figure 10.1: Cross-correlation function (CCF) against delay distance for the CBP dataset. The delay with the maximum correlation is shown as the red line.
10.3.2 Counting reads into windows
Reads are then counted into sliding windows using csaw (Lun and Smyth 2016). For TF data analyses, smaller windows are necessary to capture sharp binding sites. A large window size will be suboptimal as the count for a particular site will be “contaminated” by non-specific background in the neighbouring regions. In this case, a window size of 10 bp is used.
## class: RangedSummarizedExperiment
## dim: 9952827 4
## metadata(6): spacing width ... param final.ext
## assays(1): counts
## rownames: NULL
## rowData names(0):
## colnames: NULL
## colData names(4): bam.files totals ext rlenThe default spacing of 50 bp is also used here.
This may seem inappropriate given that the windows are only 10 bp.
However, reads lying in the interval between adjacent windows will still be counted into several windows.
This is because reads are extended to the value of frag.len, which is substantially larger than the 50 bp spacing10.
10.4 Filtering of low-abundance windows
We remove low-abundance windows by computing the coverage in each window relative to a global estimate of background enrichment (Section 4.4). The majority of windows in background regions are filtered out upon applying a modest fold-change threshold. This leaves a small set of relevant windows for further analysis.
bins <- windowCounts(cbpdata$Path, bin=TRUE, width=10000, param=param)
filter.stat <- filterWindowsGlobal(win.data, bins)
min.fc <- 3
keep <- filter.stat$filter > log2(min.fc)
summary(keep)## Mode FALSE TRUE
## logical 9652836 299991Note that the 10 kbp bins are used here for filtering, while smaller 2 kbp bins were used in the corresponding step for the H3K9ac analysis. This is purely for convenience – the 10 kbp counts for this dataset were previously loaded for normalization, and can be re-used during filtering to save time. Changes in bin size will have little impact on the results, so long as the bins (and their counts) are large enough for precise estimation of the background abundance. While smaller bins provide greater spatial resolution, this is irrelevant for quantifying coverage in large background regions that span most of the genome.
10.5 Normalization for composition biases
We expect unbalanced DB in this dataset as CBP function should be compromised in the KO cells,
such that most - if not all - of the DB sites should exhibit increased CBP binding in the WT condition.
To remove this bias, we assign reads to large genomic bins and assume that most bins represent non-DB background regions (Lun and Smyth 2014).
Any systematic differences in the coverage of those bins is attributed to composition bias and is normalized out.
Specifically, the trimmed mean of M-values (TMM) method (Robinson and Oshlack 2010) is applied to compute normalization factors from the bin counts.
These factors are stored in win.data11 so that they will be applied during the DB analysis with the window counts.
## [1] 1.0126 0.9083 1.0444 1.0411We visualize the effect of normalization with mean-difference plots between pairs of samples (Figure 10.2). The dense cloud in each plot represents the majority of bins in the genome. These are assumed to mostly contain background regions. A non-zero log-fold change for these bins indicates that composition bias is present between samples. The red line represents the log-ratio of normalization factors and passes through the centre of the cloud in each plot, indicating that the bias has been successfully identified and removed.
bin.ab <- scaledAverage(bins)
adjc <- calculateCPM(bins, use.norm.factors=FALSE)
par(cex.lab=1.5, mfrow=c(1,3))
smoothScatter(bin.ab, adjc[,1]-adjc[,4], ylim=c(-6, 6),
xlab="Average abundance", ylab="Log-ratio (1 vs 4)")
abline(h=log2(normfacs[1]/normfacs[4]), col="red")
smoothScatter(bin.ab, adjc[,2]-adjc[,4], ylim=c(-6, 6),
xlab="Average abundance", ylab="Log-ratio (2 vs 4)")
abline(h=log2(normfacs[2]/normfacs[4]), col="red")
smoothScatter(bin.ab, adjc[,3]-adjc[,4], ylim=c(-6, 6),
xlab="Average abundance", ylab="Log-ratio (3 vs 4)")
abline(h=log2(normfacs[3]/normfacs[4]), col="red")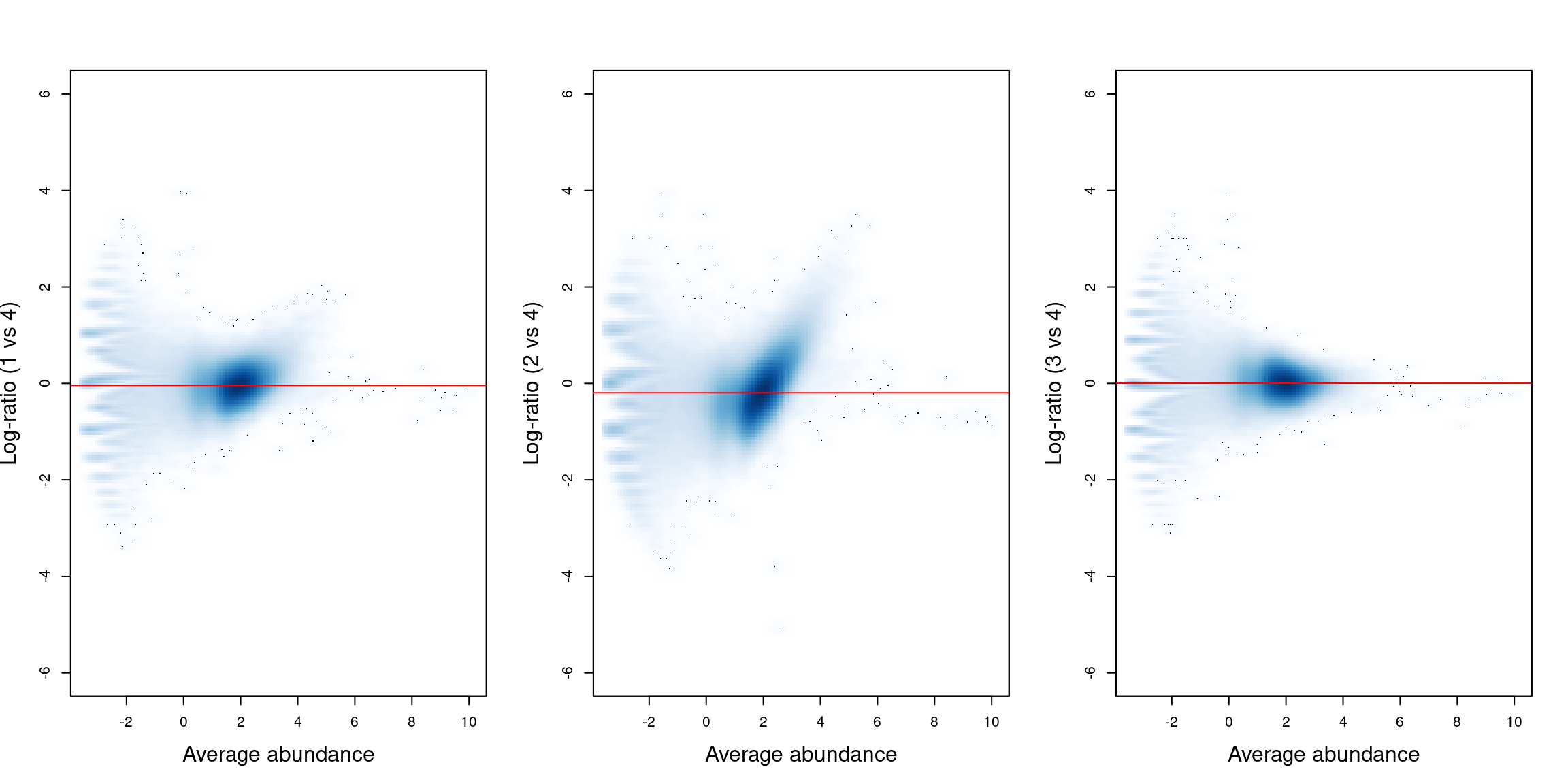
Figure 10.2: Mean-difference plots for the bin counts, comparing sample 4 to all other samples. The red line represents the log-ratio of the normalization factors between samples.
Note that this normalization strategy is quite different from that in the H3K9ac analysis. Here, systematic DB in one direction is expected between conditions, given that CBP function is lost in the KO genotype. This means that the assumption of a non-DB majority (required for non-linear normalization of the H3K9ac data) is not valid. No such assumption is made by the binned-TMM approach described above, which makes it more appropriate for use in the CBP analysis.
10.6 Statistical modelling
We model counts for each window using edgeR (McCarthy, Chen, and Smyth 2012; Robinson, McCarthy, and Smyth 2010).
First, we convert our RangedSummarizedExperiment object into a DGEList.
## Length Class Mode
## counts 1199964 -none- numeric
## samples 3 data.frame listWe then construct a design matrix for our experimental design. Again, we have a simple one-way layout with two groups of two replicates.
genotype <- cbpdata$Description
genotype[grep("wild-type", genotype)] <- "wt"
genotype[grep("knock-out", genotype)] <- "ko"
genotype <- factor(genotype)
design <- model.matrix(~0+genotype)
colnames(design) <- levels(genotype)
design## ko wt
## 1 0 1
## 2 0 1
## 3 1 0
## 4 1 0
## attr(,"assign")
## [1] 1 1
## attr(,"contrasts")
## attr(,"contrasts")$genotype
## [1] "contr.treatment"We estimate the negative binomial (NB) and quasi-likelihood (QL) dispersions for each window (Lund et al. 2012). The estimated NB dispersions (Figure 10.3) are substantially larger than those observed in the H3K9ac dataset. They also exhibit an unusual increasing trend with respect to abundance.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.102 0.129 0.146 0.152 0.176 0.214
Figure 10.3: Abundance-dependent trend in the biological coefficient of variation (i.e., the root-NB dispersion) for each window, represented by the blue line. Common (red) and tagwise estimates (black) are also shown.
The estimated prior d.f. is also infinite, meaning that all the QL dispersions are equal to the trend (Figure 10.4).
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 48426 Inf Inf Inf Inf Inf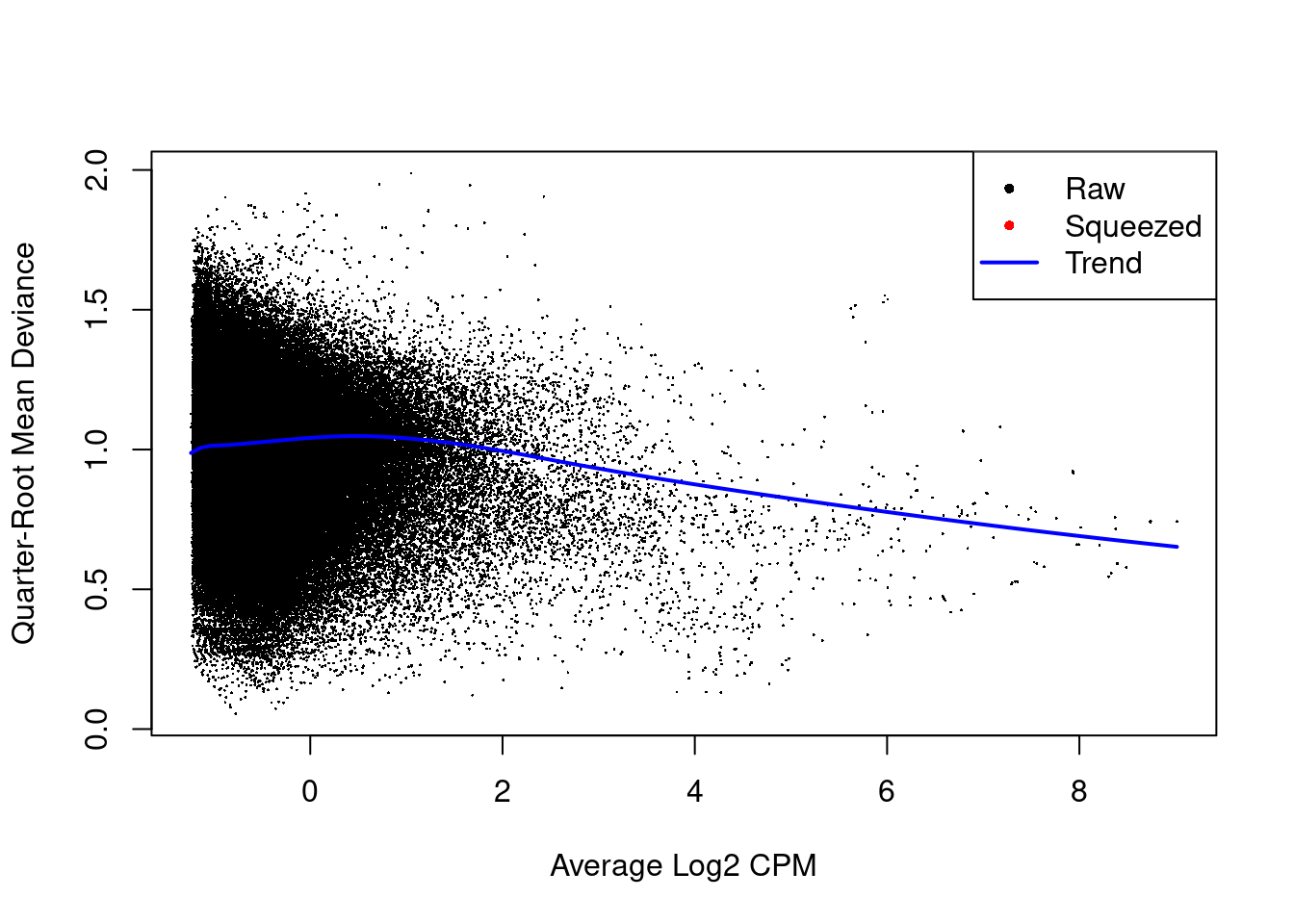
Figure 10.4: Effect of EB shrinkage on the raw QL dispersion estimate for each window (black) towards the abundance-dependent trend (blue) to obtain squeezed estimates (red). Quarter-root estimates are shown for greater dynamic range.
These results are consistent with the presence of a systematic difference in CBP enrichment between the WT replicates. An increasing trend in Figure 10.3 is typical after normalization for composition biases, where replicates exhibit some differences in efficiency that manifest as increased dispersions at high abundance. The dispersions for all windows are inflated to a similarly large value by this difference, manifesting as low variability in the dispersions across windows. This effect is illustrated in Figure 10.5 where the WT samples are clearly separated in both dimensions.

Figure 10.5: MDS plot with two dimensions for all samples in the CBP dataset. Samples are labelled and coloured according to the genotype. A larger top set of windows was used to improve the visualization of the genome-wide differences between the WT samples.
The presence of a large batch effect between replicates is not ideal. Nonetheless, we can still proceed with the DB analysis - albeit with some loss of power due to the inflated NB dispersions - given that there are strong differences between genotypes in Figure 10.5,
10.7 Testing for DB
We test for a significant difference in binding between genotypes in each window using the QL F-test.
Windows less than 100 bp apart are clustered into regions (Lun and Smyth 2014) with a maximum cluster width of 5 kbp. We then control the region-level FDR by combining per-window \(p\)-values using Simes’ method (Simes 1986).
merged <- mergeResults(filtered.data, res$table, tol=100,
merge.args=list(max.width=5000))
merged$regions## GRanges object with 61773 ranges and 0 metadata columns:
## seqnames ranges strand
## <Rle> <IRanges> <Rle>
## [1] chr1 3613551-3613610 *
## [2] chr1 4785501-4785860 *
## [3] chr1 4807601-4808010 *
## [4] chr1 4857451-4857910 *
## [5] chr1 4858301-4858460 *
## ... ... ... ...
## [61769] chrY 90808801-90808910 *
## [61770] chrY 90810901-90810910 *
## [61771] chrY 90811301-90811360 *
## [61772] chrY 90811601-90811660 *
## [61773] chrY 90811851-90813910 *
## -------
## seqinfo: 66 sequences from an unspecified genome## Mode FALSE TRUE
## logical 58053 3720All significant regions have increased CBP binding in the WT genotype. This is expected given that protein function should be lost in the KO genotype.
##
## down up
## 2 3718# Direction according the best window in each cluster.
tabbest <- merged$best
is.sig.pos <- (tabbest$rep.logFC > 0)[is.sig]
summary(is.sig.pos)## Mode FALSE TRUE
## logical 2 3718We save the results to file in the form of a serialized R object for later inspection.
10.8 Annotation and visualization
We annotate each region using the detailRanges() function.
library(TxDb.Mmusculus.UCSC.mm10.knownGene)
library(org.Mm.eg.db)
anno <- detailRanges(out.ranges, orgdb=org.Mm.eg.db,
txdb=TxDb.Mmusculus.UCSC.mm10.knownGene)
mcols(out.ranges) <- cbind(mcols(out.ranges), anno)We visualize one of the top-ranked DB regions here. This corresponds to a simple DB event as all windows are changing in the same direction, i.e., up in the WT. The binding region is also quite small relative to some of the H3K9ac examples, consistent with sharp TF binding to a specific recognition site.
## GRanges object with 1 range and 13 metadata columns:
## seqnames ranges strand | num.tests num.up.logFC
## <Rle> <IRanges> <Rle> | <integer> <integer>
## [1] chr3 145758501-145759510 * | 21 17
## num.down.logFC PValue FDR direction rep.test rep.logFC
## <integer> <numeric> <numeric> <character> <integer> <numeric>
## [1] 0 4.45747e-13 1.03695e-08 up 189312 4.29456
## best.pos best.logFC overlap left right
## <integer> <numeric> <character> <character> <character>
## [1] 145759055 4.29456 Ddah1:+:PE Ddah1:+:1238
## -------
## seqinfo: 66 sequences from an unspecified genomeWe use Gviz (F. and R. 2016) to plot the results. As in the H3K9ac analysis, we set up some tracks to display genome coordinates and gene annotation.
library(Gviz)
gax <- GenomeAxisTrack(col="black", fontsize=15, size=2)
greg <- GeneRegionTrack(TxDb.Mmusculus.UCSC.mm10.knownGene, showId=TRUE,
geneSymbol=TRUE, name="", background.title="transparent")
symbols <- unlist(mapIds(org.Mm.eg.db, gene(greg), "SYMBOL",
"ENTREZID", multiVals = "first"))
symbol(greg) <- symbols[gene(greg)]We visualize two tracks for each sample – one for the forward-strand coverage, another for the reverse-strand coverage. This allows visualization of the strand bimodality that is characteristic of genuine TF binding sites. In Figure 10.6, two adjacent sites are present at the Gbe1 promoter, both of which exhibit increased binding in the WT genotype. Coverage is also substantially different between the WT replicates, consistent with the presence of a batch effect.
collected <- list()
lib.sizes <- filtered.data$totals/1e6
for (i in seq_along(cbpdata$Path)) {
reads <- extractReads(bam.file=cbpdata$Path[[i]], cur.region, param=param)
pcov <- as(coverage(reads[strand(reads)=="+"])/lib.sizes[i], "GRanges")
ncov <- as(coverage(reads[strand(reads)=="-"])/-lib.sizes[i], "GRanges")
ptrack <- DataTrack(pcov, type="histogram", lwd=0, ylim=c(-5, 5),
name=cbpdata$Description[i], col.axis="black", col.title="black",
fill="blue", col.histogram=NA)
ntrack <- DataTrack(ncov, type="histogram", lwd=0, ylim=c(-5, 5),
fill="red", col.histogram=NA)
collected[[i]] <- OverlayTrack(trackList=list(ptrack, ntrack))
}
plotTracks(c(gax, collected, greg), chromosome=as.character(seqnames(cur.region)),
from=start(cur.region), to=end(cur.region))
Figure 10.6: Coverage tracks for TF binding sites that are differentially bound in the WT (top two tracks) against the KO (last two tracks). Blue and red tracks represent forward- and reverse-strand coverage, respectively, on a per-million scale (capped at 5 in SRR1145788, for visibility).
Session information
R version 4.3.1 (2023-06-16)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 22.04.3 LTS
Matrix products: default
BLAS: /home/biocbuild/bbs-3.18-bioc/R/lib/libRblas.so
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.10.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_GB LC_COLLATE=C
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
time zone: America/New_York
tzcode source: system (glibc)
attached base packages:
[1] grid stats4 stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] Gviz_1.46.0
[2] org.Mm.eg.db_3.18.0
[3] TxDb.Mmusculus.UCSC.mm10.knownGene_3.10.0
[4] GenomicFeatures_1.54.0
[5] AnnotationDbi_1.64.0
[6] edgeR_4.0.0
[7] limma_3.58.0
[8] csaw_1.36.0
[9] SummarizedExperiment_1.32.0
[10] Biobase_2.62.0
[11] MatrixGenerics_1.14.0
[12] matrixStats_1.0.0
[13] rtracklayer_1.62.0
[14] BiocFileCache_2.10.0
[15] dbplyr_2.3.4
[16] Rsamtools_2.18.0
[17] Biostrings_2.70.0
[18] XVector_0.42.0
[19] GenomicRanges_1.54.0
[20] GenomeInfoDb_1.38.0
[21] IRanges_2.36.0
[22] S4Vectors_0.40.0
[23] BiocGenerics_0.48.0
[24] chipseqDBData_1.17.0
[25] BiocStyle_2.30.0
[26] rebook_1.12.0
loaded via a namespace (and not attached):
[1] RColorBrewer_1.1-3 rstudioapi_0.15.0
[3] jsonlite_1.8.7 CodeDepends_0.6.5
[5] magrittr_2.0.3 rmarkdown_2.25
[7] BiocIO_1.12.0 zlibbioc_1.48.0
[9] vctrs_0.6.4 memoise_2.0.1
[11] RCurl_1.98-1.12 base64enc_0.1-3
[13] htmltools_0.5.6.1 S4Arrays_1.2.0
[15] progress_1.2.2 AnnotationHub_3.10.0
[17] curl_5.1.0 SparseArray_1.2.0
[19] Formula_1.2-5 sass_0.4.7
[21] KernSmooth_2.23-22 bslib_0.5.1
[23] htmlwidgets_1.6.2 cachem_1.0.8
[25] GenomicAlignments_1.38.0 mime_0.12
[27] lifecycle_1.0.3 pkgconfig_2.0.3
[29] Matrix_1.6-1.1 R6_2.5.1
[31] fastmap_1.1.1 GenomeInfoDbData_1.2.11
[33] shiny_1.7.5.1 digest_0.6.33
[35] colorspace_2.1-0 ExperimentHub_2.10.0
[37] Hmisc_5.1-1 RSQLite_2.3.1
[39] filelock_1.0.2 fansi_1.0.5
[41] httr_1.4.7 abind_1.4-5
[43] compiler_4.3.1 bit64_4.0.5
[45] withr_2.5.1 backports_1.4.1
[47] htmlTable_2.4.1 BiocParallel_1.36.0
[49] DBI_1.1.3 biomaRt_2.58.0
[51] rappdirs_0.3.3 DelayedArray_0.28.0
[53] rjson_0.2.21 tools_4.3.1
[55] foreign_0.8-85 interactiveDisplayBase_1.40.0
[57] httpuv_1.6.12 nnet_7.3-19
[59] glue_1.6.2 restfulr_0.0.15
[61] promises_1.2.1 checkmate_2.2.0
[63] cluster_2.1.4 generics_0.1.3
[65] gtable_0.3.4 BSgenome_1.70.0
[67] ensembldb_2.26.0 data.table_1.14.8
[69] hms_1.1.3 metapod_1.10.0
[71] xml2_1.3.5 utf8_1.2.4
[73] BiocVersion_3.18.0 pillar_1.9.0
[75] stringr_1.5.0 later_1.3.1
[77] splines_4.3.1 dplyr_1.1.3
[79] lattice_0.22-5 deldir_1.0-9
[81] bit_4.0.5 biovizBase_1.50.0
[83] tidyselect_1.2.0 locfit_1.5-9.8
[85] knitr_1.44 gridExtra_2.3
[87] bookdown_0.36 ProtGenerics_1.34.0
[89] xfun_0.40 statmod_1.5.0
[91] stringi_1.7.12 lazyeval_0.2.2
[93] yaml_2.3.7 evaluate_0.22
[95] codetools_0.2-19 interp_1.1-4
[97] tibble_3.2.1 BiocManager_1.30.22
[99] graph_1.80.0 cli_3.6.1
[101] rpart_4.1.21 xtable_1.8-4
[103] munsell_0.5.0 jquerylib_0.1.4
[105] dichromat_2.0-0.1 Rcpp_1.0.11
[107] dir.expiry_1.10.0 png_0.1-8
[109] XML_3.99-0.14 parallel_4.3.1
[111] ellipsis_0.3.2 ggplot2_3.4.4
[113] blob_1.2.4 prettyunits_1.2.0
[115] jpeg_0.1-10 latticeExtra_0.6-30
[117] AnnotationFilter_1.26.0 bitops_1.0-7
[119] VariantAnnotation_1.48.0 scales_1.2.1
[121] purrr_1.0.2 crayon_1.5.2
[123] rlang_1.1.1 KEGGREST_1.42.0 Bibliography
Consortium, ENCODE Project. 2012. “An integrated encyclopedia of DNA elements in the human genome.” Nature 489 (7414): 57–74.
F., Hahne, and Ivanek R. 2016. “Visualizing Genomic Data Using Gviz and Bioconductor.” In Statistical Genomics: Methods and Protocols, edited by Ewy Mathé and Sean Davis, 335–51. New York, NY: Springer New York. https://doi.org/10.1007/978-1-4939-3578-9_16.
Kasper, L. H., C. Qu, J. C. Obenauer, D. J. McGoldrick, and P. K. Brindle. 2014. “Genome-wide and single-cell analyses reveal a context dependent relationship between CBP recruitment and gene expression.” Nucleic Acids Res. 42 (18): 11363–82.
Lun, A. T., and G. K. Smyth. 2014. “De novo detection of differentially bound regions for ChIP-seq data using peaks and windows: controlling error rates correctly.” Nucleic Acids Res. 42 (11): e95.
Lun, A. 2016. “csaw: a Bioconductor package for differential binding analysis of ChIP-seq data using sliding windows.” Nucleic Acids Res. 44 (5): e45.
Lund, S. P., D. Nettleton, D. J. McCarthy, and G. K. Smyth. 2012. “Detecting differential expression in RNA-sequence data using quasi-likelihood with shrunken dispersion estimates.” Stat. Appl. Genet. Mol. Biol. 11 (5).
McCarthy, D. J., Y. Chen, and G. K. Smyth. 2012. “Differential expression analysis of multifactor RNA-Seq experiments with respect to biological variation.” Nucleic Acids Res. 40 (10): 4288–97.
Robinson, M. D., D. J. McCarthy, and G. K. Smyth. 2010. “edgeR: a Bioconductor package for differential expression analysis of digital gene expression data.” Bioinformatics 26 (1): 139–40.
Robinson, M. D., and A. Oshlack. 2010. “A scaling normalization method for differential expression analysis of RNA-seq data.” Genome Biol. 11 (3): R25.
Simes, R. J. 1986. “An Improved Bonferroni Procedure for Multiple Tests of Significance.” Biometrika 73 (3): 751–54.