
![]()
Gain insight into your models!
When fitting any statistical model, there are many useful pieces of information that are simultaneously calculated and stored beyond coefficient estimates and general model fit statistics. Although there exist some generic functions to obtain model information and data, many package-specific modelling functions do not provide such methods to allow users to access such valuable information.
insight is an R-package that fills this important gap by providing a suite of functions to support almost any model (see a list of the many models supported below in the List of Supported Packages and Models section). The goal of insight, then, is to provide tools to provide easy, intuitive, and consistent access to information contained in model objects. These tools aid applied research in virtually any field who fit, diagnose, and present statistical models by streamlining access to every aspect of many model objects via consistent syntax and output.
![]()
The insight package is available on CRAN, while its latest development version is available on R-universe (from rOpenSci) or GitHub.
| Type | Source | Command |
|---|---|---|
| Release | CRAN | install.packages("insight") |
| Development | r-universe | install.packages("insight", repos = "https://easystats.r-universe.dev") |
| Development | GitHub | remotes::install_github("easystats/insight") |
Once you have downloaded the package, you can then load it using:
Tip
Instead of
library(insight), uselibrary(easystats). This will make all features of the easystats-ecosystem available.To stay updated, use
easystats::install_latest().
![]()
![]()
![]()
Built with non-programmers in mind, insight offers a broad toolbox for making model and data information easily accessible. While insight offers many useful functions for working with and understanding model objects (discussed below), we suggest users start with model_info(), as this function provides a clean and consistent overview of model objects (e.g., functional form of the model, the model family, link function, number of observations, variables included in the specification, etc.). With a clear understanding of the model introduced, users are able to adapt other functions for more nuanced exploration of and interaction with virtually any model object.Please visit https://easystats.github.io/insight/ for documentation.
The functions from insight address different components of a model. In an effort to avoid confusion about specific “targets” of each function, in this section we provide a short explanation of insight’s definitions of regression model components.
The dataset used to fit the model.
Values estimated or learned from data that capture the relationship between variables. In regression models, these are usually referred to as coefficients.
Any unique variable names that appear in a regression model, e.g., response variable, predictors or random effects. A “variable” only relates to the unique occurence of a term, or the term name. For instance, the expression x + poly(x, 2) has only the variable x.
Terms themselves consist of variable and factor names separated by operators, or involve arithmetic expressions. For instance, the expression x + poly(x, 2) has one variable x, but two terms x and poly(x, 2).
Aren’t the predictors, terms and parameters the same thing?
In some cases, yes. But not in all cases. Find out more by clicking here to access the documentation.
The package revolves around two key prefixes: get_* and find_*. The get_* prefix extracts values (or data) associated with model-specific objects (e.g., parameters or variables), while the find_* prefix lists model-specific objects (e.g., priors or predictors). These are powerful families of functions allowing for great flexibility in use, whether at a high, descriptive level (find_*) or narrower level of statistical inspection and reporting (get_*).
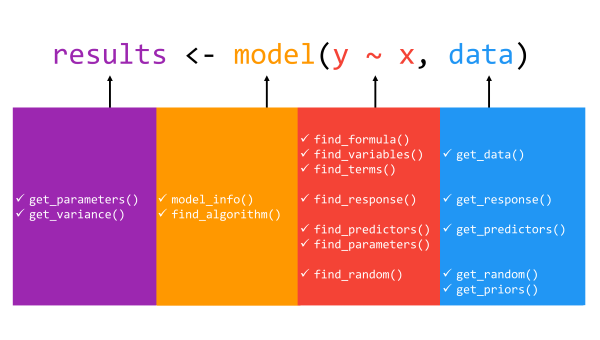
In total, the insight package includes 16 core functions: get_data(), get_priors(), get_variance(), get_parameters(), get_predictors(), get_random(), get_response(), find_algorithm(), find_formula(), find_variables(), find_terms(), find_parameters(), find_predictors(), find_random(), find_response(), and model_info(). In all cases, users must supply at a minimum, the name of the model fit object. In several functions, there are additional arguments that allow for more targeted returns of model information. For example, the find_terms() function’s effects argument allows for the extraction of “fixed effects” terms, “random effects” terms, or by default, “all” terms in the model object. We point users to the package documentation or the complementary package website, https://easystats.github.io/insight/, for a detailed list of the arguments associated with each function as well as the returned values from each function.
We now would like to provide examples of use cases of the insight package. These examples probably do not cover typical real-world problems, but serve as illustration of the core idea of this package: The unified interface to access model information. insight should help both users and package developers in order to reduce the hassle with the many exceptions from various modelling packages when accessing model information.
Say, the goal is to make predictions for a certain term, holding remaining co-variates constant. This is achieved by calling predict() and feeding the newdata-argument with the values of the term of interest as well as the “constant” values for remaining co-variates. The functions get_data() and find_predictors() are used to get this information, which then can be used in the call to predict().
In this example, we fit a simple linear model, but it could be replaced by (m)any other models, so this approach is “universal” and applies to many different model objects.
library(insight)
m <- lm(
Sepal.Length ~ Species + Petal.Width + Sepal.Width,
data = iris
)
dat <- get_data(m)
pred <- find_predictors(m, flatten = TRUE)
l <- lapply(pred, function(x) {
if (is.numeric(dat[[x]])) {
mean(dat[[x]])
} else {
unique(dat[[x]])
}
})
names(l) <- pred
l <- as.data.frame(l)
cbind(l, predictions = predict(m, newdata = l))
#> Species Petal.Width Sepal.Width predictions
#> 1 setosa 1.2 3.1 5.1
#> 2 versicolor 1.2 3.1 6.1
#> 3 virginica 1.2 3.1 6.3The next example should emphasize the possibilities to generalize functions to many different model objects using insight. The aim is simply to print coefficients in a complete, human readable sentence.
The first approach uses the functions that are available for some, but obviously not for all models, to access the information about model coefficients.
print_params <- function(model) {
paste0(
"My parameters are ",
toString(row.names(summary(model)$coefficients)),
", thank you for your attention!"
)
}
m1 <- lm(Sepal.Length ~ Petal.Width, data = iris)
print_params(m1)
#> [1] "My parameters are (Intercept), Petal.Width, thank you for your attention!"
# obviously, something is missing in the output
m2 <- mgcv::gam(Sepal.Length ~ Petal.Width + s(Petal.Length), data = iris)
print_params(m2)
#> [1] "My parameters are , thank you for your attention!"As we can see, the function fails for gam-models. As the access to models depends on the type of the model in the R ecosystem, we would need to create specific functions for all models types. With insight, users can write a function without having to worry about the model type.
print_params <- function(model) {
paste0(
"My parameters are ",
toString(insight::find_parameters(model, flatten = TRUE)),
", thank you for your attention!"
)
}
m1 <- lm(Sepal.Length ~ Petal.Width, data = iris)
print_params(m1)
#> [1] "My parameters are (Intercept), Petal.Width, thank you for your attention!"
m2 <- mgcv::gam(Sepal.Length ~ Petal.Width + s(Petal.Length), data = iris)
print_params(m2)
#> [1] "My parameters are (Intercept), Petal.Width, s(Petal.Length), thank you for your attention!"In case you want to file an issue or contribute in another way to the package, please follow this guide. For questions about the functionality, you may either contact us via email or also file an issue.
Currently, 226 model classes are supported.
supported_models()
#> [1] "aareg" "afex_aov"
#> [3] "AKP" "Anova.mlm"
#> [5] "anova.rms" "aov"
#> [7] "aovlist" "Arima"
#> [9] "averaging" "bamlss"
#> [11] "bamlss.frame" "bayesQR"
#> [13] "bayesx" "BBmm"
#> [15] "BBreg" "bcplm"
#> [17] "betamfx" "betaor"
#> [19] "betareg" "BFBayesFactor"
#> [21] "bfsl" "BGGM"
#> [23] "bife" "bifeAPEs"
#> [25] "bigglm" "biglm"
#> [27] "blavaan" "blrm"
#> [29] "bracl" "brglm"
#> [31] "brmsfit" "brmultinom"
#> [33] "btergm" "censReg"
#> [35] "cgam" "cgamm"
#> [37] "cglm" "clm"
#> [39] "clm2" "clmm"
#> [41] "clmm2" "clogit"
#> [43] "coeftest" "complmrob"
#> [45] "confusionMatrix" "coxme"
#> [47] "coxph" "coxph.penal"
#> [49] "coxr" "cpglm"
#> [51] "cpglmm" "crch"
#> [53] "crq" "crqs"
#> [55] "crr" "dep.effect"
#> [57] "DirichletRegModel" "draws"
#> [59] "drc" "eglm"
#> [61] "elm" "epi.2by2"
#> [63] "ergm" "feglm"
#> [65] "feis" "felm"
#> [67] "fitdistr" "fixest"
#> [69] "flac" "flexsurvreg"
#> [71] "flic" "gam"
#> [73] "Gam" "gamlss"
#> [75] "gamm" "gamm4"
#> [77] "garch" "gbm"
#> [79] "gee" "geeglm"
#> [81] "glht" "glimML"
#> [83] "glm" "Glm"
#> [85] "glmm" "glmmadmb"
#> [87] "glmmPQL" "glmmTMB"
#> [89] "glmrob" "glmRob"
#> [91] "glmx" "gls"
#> [93] "gmnl" "hglm"
#> [95] "HLfit" "htest"
#> [97] "hurdle" "iv_robust"
#> [99] "ivFixed" "ivprobit"
#> [101] "ivreg" "lavaan"
#> [103] "lm" "lm_robust"
#> [105] "lme" "lmerMod"
#> [107] "lmerModLmerTest" "lmodel2"
#> [109] "lmrob" "lmRob"
#> [111] "logistf" "logitmfx"
#> [113] "logitor" "logitr"
#> [115] "LORgee" "lqm"
#> [117] "lqmm" "lrm"
#> [119] "manova" "MANOVA"
#> [121] "marginaleffects" "marginaleffects.summary"
#> [123] "margins" "maxLik"
#> [125] "mblogit" "mclogit"
#> [127] "mcmc" "mcmc.list"
#> [129] "MCMCglmm" "mcp1"
#> [131] "mcp12" "mcp2"
#> [133] "med1way" "mediate"
#> [135] "merMod" "merModList"
#> [137] "meta_bma" "meta_fixed"
#> [139] "meta_random" "metaplus"
#> [141] "mhurdle" "mipo"
#> [143] "mira" "mixed"
#> [145] "MixMod" "mixor"
#> [147] "mjoint" "mle"
#> [149] "mle2" "mlm"
#> [151] "mlogit" "mmclogit"
#> [153] "mmlogit" "mmrm"
#> [155] "mmrm_fit" "mmrm_tmb"
#> [157] "model_fit" "multinom"
#> [159] "mvord" "negbinirr"
#> [161] "negbinmfx" "nestedLogit"
#> [163] "ols" "onesampb"
#> [165] "orm" "pgmm"
#> [167] "phyloglm" "phylolm"
#> [169] "plm" "PMCMR"
#> [171] "poissonirr" "poissonmfx"
#> [173] "polr" "probitmfx"
#> [175] "psm" "Rchoice"
#> [177] "ridgelm" "riskRegression"
#> [179] "rjags" "rlm"
#> [181] "rlmerMod" "RM"
#> [183] "rma" "rma.uni"
#> [185] "robmixglm" "robtab"
#> [187] "rq" "rqs"
#> [189] "rqss" "rvar"
#> [191] "Sarlm" "scam"
#> [193] "selection" "sem"
#> [195] "SemiParBIV" "semLm"
#> [197] "semLme" "serp"
#> [199] "slm" "speedglm"
#> [201] "speedlm" "stanfit"
#> [203] "stanmvreg" "stanreg"
#> [205] "summary.lm" "survfit"
#> [207] "survreg" "svy_vglm"
#> [209] "svychisq" "svyglm"
#> [211] "svyolr" "t1way"
#> [213] "tobit" "trimcibt"
#> [215] "truncreg" "vgam"
#> [217] "vglm" "wbgee"
#> [219] "wblm" "wbm"
#> [221] "wmcpAKP" "yuen"
#> [223] "yuend" "zcpglm"
#> [225] "zeroinfl" "zerotrunc"If this package helped you, please consider citing as follows:
Lüdecke D, Waggoner P, Makowski D. insight: A Unified Interface to Access Information from Model Objects in R. Journal of Open Source Software 2019;4:1412. doi: 10.21105/joss.01412
Please note that the insight project is released with a Contributor Code of Conduct. By contributing to this project, you agree to abide by its terms.