![]()
![]()
Main features • References • Installation • Overview • Data model • Databases • Example workflow • Analysis across registers • Tests, coverage • Acknowledgements • Future
The package ctrdata provides functions for retrieving
(downloading), aggregating and analysing clinical trials using
information (structured protocol and result data, as well as documents)
from public registers. It can be used with the
The motivation is to investigate the design and conduct of trials of
interest, to describe their trends and availability for patients and to
facilitate using their detailed results for research and meta-analyses.
ctrdata is a package for the R system, but other systems and
tools can use the databases created with this package. This README was
reviewed on 2025-11-30 for version 1.25.0.9000.
Trial information is easily found and downloaded: Users generate
queries with ctrdata for all registers or define a query in
a register’s web interface, then copy the URL and enter it into
ctrdata which retrieves in one go all protocol- and
results-related trials data. A script
can automate copying the query URL from all registers. Personal
annotations can be made when downloading trials. Also, trial documents and historic
versions as available in registers on trials can be
downloaded.
Downloaded trial information is stored in a document-centric
database, for fast and offline access. Information from different
registers can be accumulated in a single collection. Uses
RSQLite, DuckDB, PostgreSQL or
MongoDB, see Databases.
Interactively browse through trial structure and data. Easily re-run any
previous query in a collection to update trial records.
For analyses, ctrdata functions implement canonical
trial
concepts to simplify analyses across registers, find synonyms of an
active substance, identify unique (de-duplicated) trial records across
all registers, merge and recode fields as well as easily access
deeply-nested fields. Analyses can be done with R (see vignette)
and other systems, using the stored JSON-structured
data.
Respect the registers’ terms and conditions, see
ctrOpenSearchPagesInBrowser(copyright = TRUE). Please cite
the package in a publication as follows: “Ralf Herold (2025).
ctrdata: Retrieve and Analyze Clinical Trials in Public
Registers. R package version 1.25.0, https://cran.r-project.org/package=ctrdata”.
An introduction to the package, together with worked examples and technical explanations is in:
Package ctrdata has been used for unpublished works and
these publications:
ctrdata in RPackage ctrdata is on CRAN and on GitHub. Within R, use the following commands to
install package ctrdata:
# Install CRAN version:
install.packages("ctrdata")
# Alternatively, install development version:
install.packages("devtools")
devtools::install_github("rfhb/ctrdata", build_vignettes = TRUE)These commands also install the package’s dependencies
(jsonlite, httr2, xml2,
nodbi, stringi, lubridate,
jqr, dplyr, zip,
readr, rlang, htmlwidgets,
stringdist and V8).
Optional; works with all registers supported by ctrdata
and is recommended for CTIS so that its URL in the web browser reflects
the user’s parameters for querying this register.
In the web browser, install the Tampermonkey browser extension,
click on “New user script” and then on “Tools”, enter into “Import from
URL” this URL: https://raw.githubusercontent.com/rfhb/ctrdata/master/tools/ctrdataURLcopier.js
and then click on “Install”.
The browser extension can be disabled and enabled by the user. When
enabled, the URLs to all user’s queries in the registers are
automatically copied to the clipboard and can be pasted into the
queryterm = ... parameter of function ctrLoadQueryIntoDb().
Additionally, this script retrieves results for CTIS
when opening search URLs such as https://euclinicaltrials.eu/ctis-public/search#searchCriteria={"status":[3,4]}.
After changing the URL in the browser, a “Reload page” is needed to
conduct the search and show results.
ctrdataSelected functions are listed in the approximate order of use in a user’s workflow (in bold, main functions). See all functions in the package documentation overview.
| Function name | Function purpose |
|---|---|
ctrGenerateQueries() |
From simple user parameters, generates queries for each register to find trials of interest |
ctrOpenSearchPagesInBrowser() |
Open search pages of registers or execute search in web browser |
ctrLoadQueryIntoDb() |
Retrieve (download) or update, and annotate, information on trials from a register and store in a collection in a database |
ctrShowOneTrial() |
Show full structure and all data of a trial, interactively select
fields of interest for dbGetFieldsIntoDf() |
dbFindFields() |
Find names of variables (fields) in the collection |
dbGetFieldsIntoDf() |
Create a data frame (or tibble) from trial records in the database with specific fields and trial concepts of interest calculated across registered, see trial concepts for 20 trial concepts available |
dfTrials2Long() |
Transform the data.frame from dbGetFieldsIntoDf() into
a long name-value data.frame, including deeply nested fields |
dfName2Value() |
From a long name-value data.frame, extract values for variables (fields) of interest (e.g., endpoints) |
ctrdataPackage ctrdata uses the data models that are implicit
in data as retrieved from the different registers. No mapping is
provided for any register’s data model to a putative target data model.
The reasons include that registers’ data models are continually evolving
over time, that only few data fields have similar values and meaning
between registers, and that the retrieved public data may not correspond
to the registers’ internal data model. The structure of data for a
specific trial can interactively be inspected and searched using
function, see the section below.
Thus, the handling of data from different models of registers is to
be done at the time of analysis. This approach allows a high level of
flexibility, transparency and reproducibility. To support analyses,
ctrdata (from version 1.21.0) provides functions that
calculate concepts of clinical trials across registers, which are
commonly used in analyses, such as start dates, age groups and
statistical tests of results. See help(ctrdata-trial-concepts)
and the section Analysis
across trials in the example workflow below. For further analyses,
see examples of function dfMergeVariablesRelevel()
on how to align related fields from different registers for a joint
analysis.
In any of the databases,
one clinical trial is one document, corresponding to one row in a
SQLite, PostgreSQL or DuckDB
table, and to one document in a MongoDB collection. These
NoSQL backends allow documents to have different
structures, which is used here to accommodate the different models of
data retrieved from the registers. Package ctrdata stores
in every such document:
_id with the trial identification as provided by
the register from which it was retrievedctrname with the name of the register
(EUCTR, CTGOV, CTGOV2,
ISRCTN, CTIS) from which that trial was
retrievedrecord_last_import with the date and time when
that document was last updated using
ctrLoadQueryIntoDb()CTGOV2 and CTIS: object
history with a historic version of the trial and with
history_version, which contains the fields
version_number (starting from 1) and
version_dateFor visualising the data structure for a trial, see this vignette section.
ctrdataPackage ctrdata retrieves trial data and stores it in a
database collection, which has to be given as a connection object to
parameter con for several ctrdata functions.
This connection object is created almost identically for the four
database backends supported by ctrdata, as shown in the
table. For a speed comparison, see the nodbi
documentation.
Besides ctrdata functions below, such a connection
object can be used with functions of other packages, such as
nodbi (see last row in table) or, in case of MongoDB as
database backend, mongolite (see vignettes).
| Purpose | Function call |
|---|---|
| Create SQLite database connection | dbc <- nodbi::src_sqlite(dbname = "name_of_my_database", collection = "name_of_my_collection") |
| Create DuckDB database connection | dbc <- nodbi::src_duckdb(dbdir = "name_of_my_database", collection = "name_of_my_collection") |
| Create MongoDB database connection | dbc <- nodbi::src_mongo(db = "name_of_my_database", collection = "name_of_my_collection") |
| Create PostgreSQL database connection | dbc <- nodbi::src_postgres(dbname = "name_of_my_database"); dbc[["collection"]] <- "name_of_my_collection" |
Use connection with ctrdata functions |
ctrdata::{ctrLoadQueryIntoDb, dbQueryHistory, dbFindIdsUniqueTrials, dbFindFields, dbGetFieldsIntoDf}(con = dbc, ...) |
Use connection with nodbi functions |
e.g.,
nodbi::docdb_query(src = dbc, key = dbc$collection, ...) |
The aim is to download protocol-related trial information and tabulate the trials’ status of conduct.
ctrdata:library(ctrdata)ctrdata:help("ctrdata")ctrdata (last updated 2025-11-25):help("ctrdata-registers")ctrOpenSearchPagesInBrowser()
# Please review and respect register copyrights:
ctrOpenSearchPagesInBrowser(copyright = TRUE)Adjust search parameters and execute search in browser
When trials of interest are listed in browser, copy the address from the browser’s address bar to the clipboard
Search used in this example: https://www.clinicaltrialsregister.eu/ctr-search/search?query=neuroblastoma&phase=phase-two&age=children
Get address from clipboard:
q <- ctrGetQueryUrl()
# * Using clipboard content as register query URL: https://www.clinicaltrialsregister.eu/
# ctr-search/search?query=neuroblastoma&phase=phase-two&age=children
# * Found search query from EUCTR: query=neuroblastoma&phase=phase-two&age=children
q
# query-term query-register
# 1 query=neuroblastoma&phase=phase-two&age=children EUCTRQueries in the trial registers can automatically copied to the clipboard (including for “CTIS”, where the URL otherwise does not show the user’s query), see here.
For loading the trial information, first a database collection is
specified, using nodbi (see above for how to specify
PostgreSQL, RSQlite, DuckDB or
MongoDB as backend, see section Databases):
# Connect to (or create) an SQLite database
# stored in a file on the local system:
db <- nodbi::src_sqlite(
dbname = "database_name.sql",
collection = "collection_name"
)Then, the trial information is retrieved and loaded into the collection:
# Retrieve trials from public register:
ctrLoadQueryIntoDb(
queryterm = q,
euctrresults = TRUE,
euctrprotocolsall = FALSE, # new since 2025-07-20, loads single
# instead of all available country versions of a trial in EUCTR
con = db
)
# * Found search query from EUCTR: query=neuroblastoma&phase=phase-two&age=children
# * Checking trials in EUCTR, found 73 trials
# - Downloading in 4 batch(es) (20 trials each; estimate: 9 MB)
# - Downloading 73 records of 73 trials (estimate: 4 s)
# - Converting to NDJSON (estimate: 0.2 s)...
# - Importing records into database...
# = Imported or updated 73 records on 73 trial(s)
# * Checking results if available from EUCTR for 73 trials:
# - Downloading results...
# - Extracting results (. = data, F = file[s] and data, x = none): . . . F . .
# . F . . F . . . . . . . F . F F . . . . . . F . . . .
# - Data found for 33 trials
# - Converting to NDJSON (estimate: 1 s)...
# - Importing 33 results into database (may take some time)...
# - Results history: not retrieved (euctrresultshistory = FALSE)
# = Imported or updated results for 33 trials
# No history found in expected format.
# Updated history ("meta-info" in "collection_name")
# $n
# [1] 73Under the hood, EUCTR plain text and XML files from EUCTR, CTGOV,
ISRCTN are converted using Javascript via V8 in
R into NDJSON, which is imported into the
database collection.
The same parameters can be used to ask ctrdata to
generate search queries that apply to each register, for opening the web
interfaces and for loading the trial data into the collection:
# Generate queries for each register
queries <- ctrGenerateQueries(
condition = "neuroblastoma",
recruitment = "completed",
phase = "phase 2",
population = "P"
)
queries
# EUCTR
#"https://www.clinicaltrialsregister.eu/ctr-search/search?query=neuroblastoma&
# phase=phase-two&age=children&age=adolescent&age=infant-and-toddler&age=
# newborn&age=preterm-new-born-infants&age=under-18&status=completed"
#
# ISRCTN
# "https://www.isrctn.com/search?&q=&filters=condition:neuroblastoma,phase:
# Phase II,ageRange:Child,trialStatus:completed,primaryStudyDesign:Interventional"
#
# CTGOV2
# "https://clinicaltrials.gov/search?cond=neuroblastoma&intr=Drug OR
# Biological&term=AREA[DesignPrimaryPurpose](DIAGNOSTIC OR PREVENTION OR
# TREATMENT)&aggFilters=phase:2,ages:child,status:com,studyType:int"
#
# CTGOV2expert
# "https://clinicaltrials.gov/expert-search?term=AREA[ConditionSearch]
# \"neuroblastoma\" AND (AREA[Phase]\"PHASE2\") AND (AREA[StdAge]\"CHILD\")
# AND (AREA[OverallStatus]\"COMPLETED\") AND (AREA[StudyType]INTERVENTIONAL)
# AND (AREA[DesignPrimaryPurpose](DIAGNOSTIC OR PREVENTION OR TREATMENT)) AND
# (AREA[InterventionSearch](DRUG OR BIOLOGICAL))"
#
# CTIS
# "https://euclinicaltrials.eu/ctis-public/search#searchCriteria=
# {\"medicalCondition\":\"neuroblastoma\",\"trialPhaseCode\":[4],
# \"ageGroupCode\":[2],\"status\":[5,8]}"
# Open queries in registers' web interfaces
sapply(queries, ctrOpenSearchPagesInBrowser)
# Load all queries into database collection
result <- lapply(queries, ctrLoadQueryIntoDb, con = db)
sapply(result, "[[", "n")
# EUCTR ISRCTN CTGOV2 CTGOV2expert CTIS
# 180 0 104 104 1Tabulate the status of trials that are part of an agreed paediatric
development program (paediatric investigation plan, PIP).
ctrdata functions return a data.frame (or a tibble, if
package tibble is loaded).
# Get all records that have values in the fields of interest:
result <- dbGetFieldsIntoDf(
# Field of interest
fields = c("a7_trial_is_part_of_a_paediatric_investigation_plan"),
# Trial concepts calculated across registers
calculate = c("f.statusRecruitment", "f.isUniqueTrial"),
con = db
)
# To review trial concepts details, call 'help("ctrdata-trial-concepts")'
# Querying database (16 fields)...
# Searching for duplicate trials...
# - Getting all trial identifiers (may take some time), 315 found in collection
# - Finding duplicates among registers' and sponsor ids...
# - 114 EUCTR _id were not preferred EU Member State record for 66 trials
# - Keeping 104 / 60 / 0 / 0 / 0 records from CTGOV2 / EUCTR / CTGOV / ISRCTN / CTIS
# = Returning keys (_id) of 164 records in collection "collection_name"
# Tabulate the clinical trial information of interest
with(
result[result$.isUniqueTrial, ],
table(
.statusRecruitment,
a7_trial_is_part_of_a_paediatric_investigation_plan
)
)
# a7_trial_is_part_of_a_paediatric_investigation_plan
# .statusRecruitment FALSE TRUE
# ongoing 6 4
# completed 11 5
# ended early 7 3
# other 8 2The new website and API introduced in July 2023 (https://www.clinicaltrials.gov/) is supported by
ctrdata since mid-2023 and identified in
ctrdata as CTGOV2.
On 2024-06-25, CTGOV has retired the classic website and
API used by ctrdata since 2015. To support users,
ctrdata automatically translates and redirects queries to
the current website. This helps with automatically updating previously
loaded queries
(ctrLoadQueryIntoDb(querytoupdate = <n>)), manually
migrating queries and reproducible work on clinical trials information.
Going forward, users are recommended to change to use
CTGOV2 queries.
As regards study data, important differences exist between field
names and contents of information retrieved using CTGOV or
CTGOV2; see the schema
for study protocols in CTGOV, the schema
for study results and the Study
Data Structure for CTGOV2. For more details, call
help("ctrdata-registers"). This is one of the reasons why
ctrdata handles the situation as if these were two
different registers and will continue to identify the current API as
register = "CTGOV2", to support the analysis stage.
Note that loading trials with ctrdata overwrites the
previous record with CTGOV2 data, whether the previous
record was retrieved using CTGOV or CTGOV2
queries.
Example using a CTGOV query:
# CTGOV search query URL
q <- "https://classic.clinicaltrials.gov/ct2/results?cond=neuroblastoma&rslt=With&recrs=e&age=0&intr=Drug"
# Open old URL (CTGOV) in current website (CTGOV2):
ctrOpenSearchPagesInBrowser(q)
# Since 2024-06-25, the classic CTGOV servers are no longer available.
# Package ctrdata has translated the classic CTGOV query URL from this call
# of function ctrLoadQueryIntoDb(queryterm = ...) into a query URL that works
# with the current CTGOV2. This is printed below and is also part of the return
# value of this function, ctrLoadQueryIntoDb(...)$url. This URL can be used with
# ctrdata functions. Note that the fields and data schema of trials differ
# between CTGOV and CTGOV2.
#
# Replace this URL:
#
# https://classic.clinicaltrials.gov/ct2/results?cond=neuroblastoma&rslt=
#With&recrs=e&age=0&intr=Drug
#
# with this URL:
#
# https://clinicaltrials.gov/search?cond=neuroblastoma&intr=Drug&aggFilters=
#ages:child,results:with,status:com
#
# * Found search query from CTGOV2: cond=neuroblastoma&intr=Drug&aggFilters=
#ages:child,results:with,status:com
# Count trials
ctrLoadQueryIntoDb(
queryterm = q,
con = db,
only.count = TRUE
)
# $n
# [1] 71Queries in the CTIS search interface can be automatically copied to
the clipboard so that a user can paste them into queryterm,
see here.
Subsequent to the relaunch of CTIS on 2024-07-24, there are more than
9,600 trials publicly accessible in CTIS. See below for how to download documents from
CTIS.
# See how many trials are in CTIS publicly accessible:
ctrLoadQueryIntoDb(
queryterm = "",
register = "CTIS",
only.count = TRUE
)
# $n
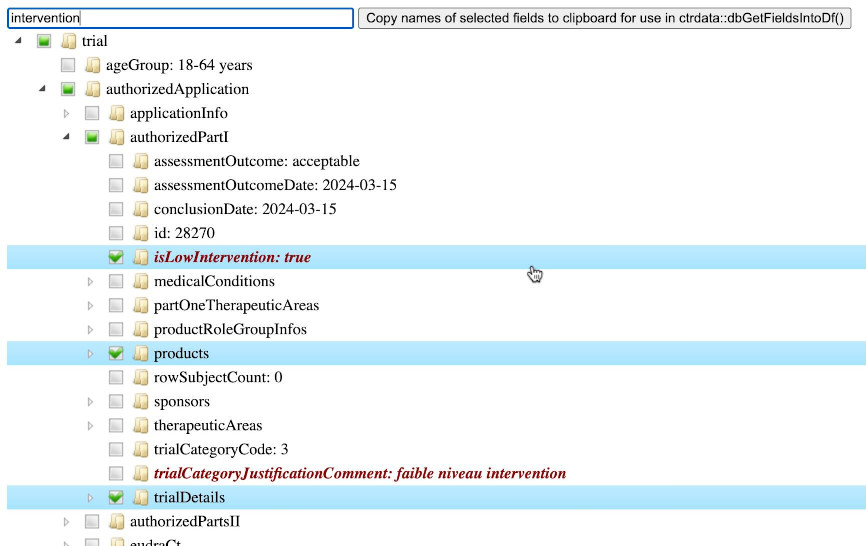
# [1] 9793For a given trial, function ctrShowOneTrial() enables the user to visualise the hiearchy of fields and contents in the user’s local web browser, to search for field names and field values, and to select and copy selected fields’ names for use with function dbGetFieldsIntoDf().
# This opens a local browser for user interaction.
# If the trial identifier (_id) is not found in the specified
# collection, it will be retrieved from the relevant register.
ctrShowOneTrial(
identifier = "2024-518931-12-00",
con = db
)
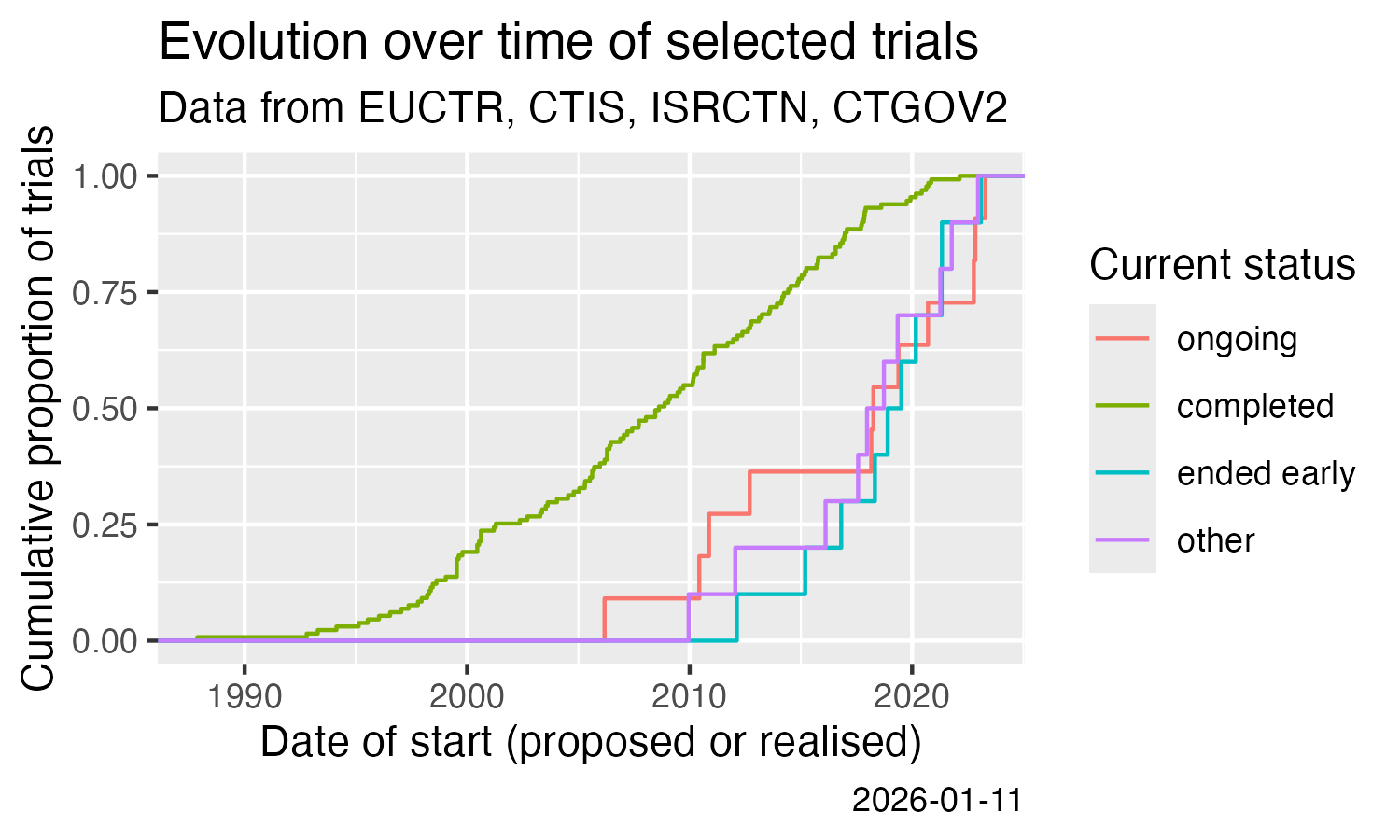
Show cumulative start of trials over time. This uses the calculation
of one of the trial concepts that are implemented in
ctrdata version 1.21.0.
# explore 20 pre-defined concepts for
# trial analysis across registers
help("ctrdata-trial-concepts")
# use helper packages
library(dplyr)
library(ggplot2)
result <- dbGetFieldsIntoDf(
calculate = c(
"f.statusRecruitment",
"f.isUniqueTrial",
"f.startDate"),
con = db
)
# To review trial concepts details, call 'help("ctrdata-trial-concepts")'
# Querying database (24 fields)...
result %>%
filter(.isUniqueTrial) %>%
ggplot() +
stat_ecdf(aes(
x = .startDate,
colour = .statusRecruitment
)) +
labs(
title = "Evolution over time of selected trials",
subtitle = "Data from EUCTR, CTIS, ISRCTN, CTGOV2",
x = "Date of start (proposed or realised)",
y = "Cumulative proportion of trials",
colour = "Current status",
caption = Sys.Date()
)
ggsave(
filename = "man/figures/README-ctrdata_across_registers.png",
width = 5, height = 3, units = "in"
)
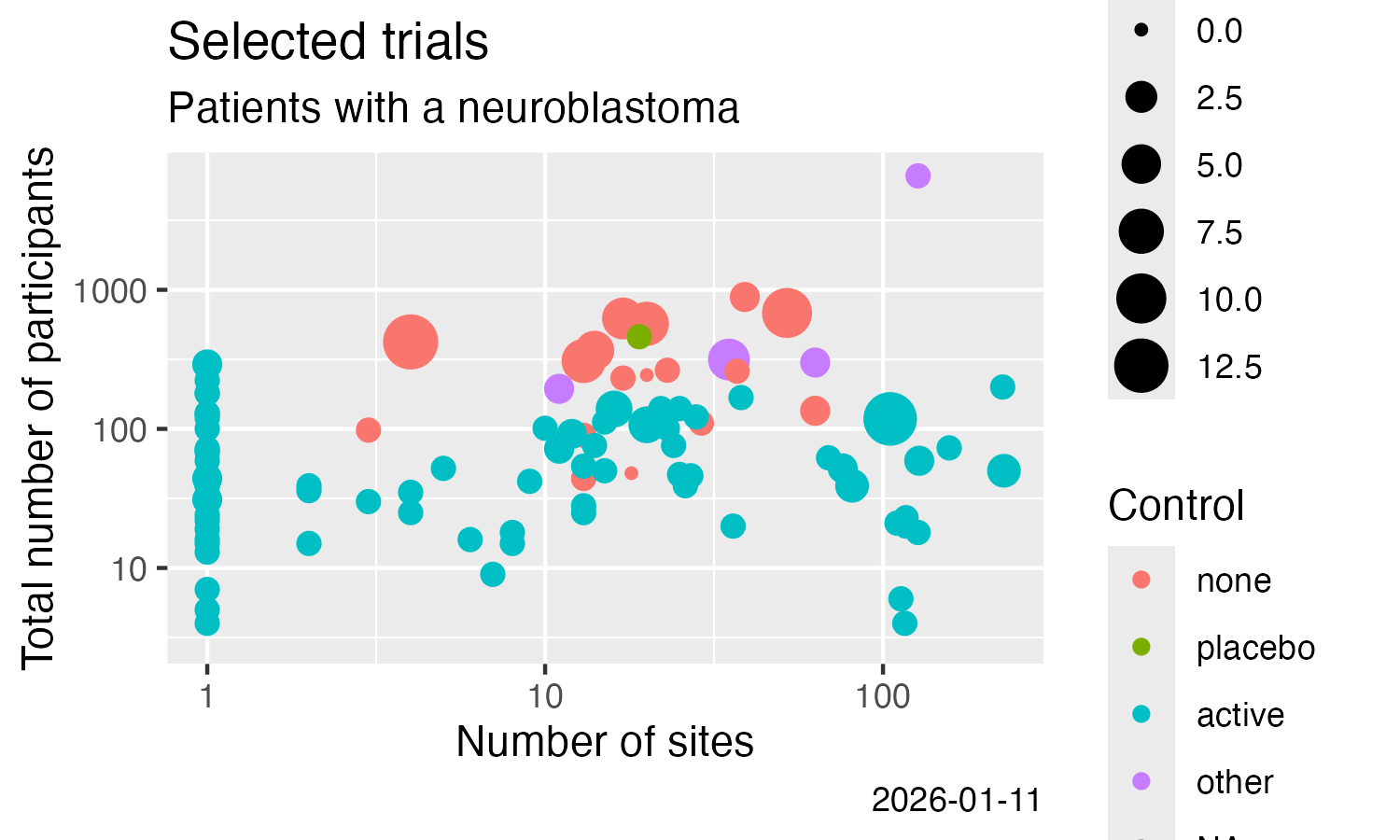
Analyse some simple result details, here from CTGOV2 (see this vignette for more examples):
# use helper packages
library(dplyr)
library(ggplot2)
result <- dbGetFieldsIntoDf(
calculate = c(
"f.numSites",
"f.sampleSize",
"f.controlType",
"f.isUniqueTrial",
"f.numTestArmsSubstances"
),
con = db
)
# To review trial concepts details, call 'help("ctrdata-trial-concepts")'
# Querying database (50 fields)...
# Calculating f.numTestArmsSubstances...
result %>%
filter(.isUniqueTrial) %>%
ggplot() +
labs(
title = "Selected trials",
subtitle = "Patients with a neuroblastoma"
) +
geom_point(
mapping = aes(
x = .numSites,
y = .sampleSize,
size = .numTestArmsSubstances,
colour = .controlType
)
) +
scale_x_log10() +
scale_y_log10() +
labs(
x = "Number of sites",
y = "Total number of participants",
colour = "Control",
size = "# Treatments",
caption = Sys.Date()
)
ggsave(
filename = "man/figures/README-ctrdata_results_neuroblastoma.png",
width = 5, height = 3, units = "in"
)
./files-.../### EUCTR document files can be downloaded when results are requested
# All files are downloaded and saved (documents.regexp is not used with EUCTR)
ctrLoadQueryIntoDb(
queryterm = "query=cancer&age=under-18&phase=phase-one",
register = "EUCTR",
euctrresults = TRUE,
euctrprotocolsall = FALSE, # new since 2025-07-20, loads single
# instead of all available country versions of a trial in EUCTR
documents.path = "./files-euctr/",
con = db
)
# * Found search query from EUCTR: query=cancer&age=under-18&phase=phase-one
# * Checking trials in EUCTR, found 249 trials
# - Running with euctrresults = TRUE to download documents
# Created directory ./files-euctr/
# - Downloading in 13 batch(es) (20 trials each; estimate: 30 MB)
# - Downloading 249 records of 249 trials (estimate: 10 s)
# - Converting to NDJSON (estimate: 0.5 s) . . . . .
# - Importing records into database...
# = Imported or updated 249 records on 249 trial(s)
# * Checking results if available from EUCTR for 249 trials:
# - Downloading results...
# - Extracting results (. = data, F = file[s] and data, x = none): F . . . . F
# . . F F . F . . . . F . . . . F . . . . . . . F . F . . F . . . . . . . F F
# . . . . . . . . . . . . . . . . . . . F F . F . . . . . . . . . . . . . . .
# . . . . . . . . . . . F . . . . . . . . . F F . . . . . . . . . . . . . . F
# . . . . F . . F . . F . . . .
# - Converting to NDJSON (estimate: 10 s)...
# - Importing results into database (may take some time)...
# - Results history: not retrieved (euctrresultshistory = FALSE)
# = Imported or updated results for 135 trials
# = Documents saved in './files-euctr'
# Updated history ("meta-info" in "collection_name")
# $n
# [1] 249
### CTGOV files are downloaded, here corresponding to the default of
# documents.regexp = "prot|sample|statist|sap_|p1ar|p2ars|icf|ctalett|lay|^[0-9]+ "
ctrLoadQueryIntoDb(
queryterm = "cond=Neuroblastoma&type=Intr&recrs=e&phase=1&u_prot=Y&u_sap=Y&u_icf=Y",
register = "CTGOV",
documents.path = "./files-ctgov/",
con = db
)
# Since 2024-06-25, the classic CTGOV servers are no longer available. Package
# ctrdata has translated the classic CTGOV query URL from this call of function
# ctrLoadQueryIntoDb(queryterm = ...) into a query URL that works with the current
# CTGOV2. This is printed below and is also part of the return value of this function, ctrLoadQueryIntoDb(...)$url. This URL can be used with ctrdata functions. Note
# that the fields and data schema of trials differ between CTGOV and CTGOV2.
#
# Replace this URL:
#
# https://classic.clinicaltrials.gov/ct2/results?cond=Neuroblastoma&type=Intr&recrs=e&phase=1&u_prot=Y&u_sap=Y&u_icf=Y
#
# with this URL:
#
# https://clinicaltrials.gov/search?cond=Neuroblastoma&aggFilters=phase:2,docs:
#prot sap icf,studyType:int,status:com
#
# * Found search query from CTGOV2: cond=Neuroblastoma&aggFilters=phase:2,docs:prot sap icf,studyType:int,status:com
# * Checking trials in CTGOV2, found 32 trials
# - Downloading in 1 batch(es) (max. 1000 trials each; estimate: 3.2 Mb total)
# - Load and convert batch 1...
# - Importing records into database...
# JSON file #: 1 / 1
# * Checking for documents...
# - Getting links to documents
# - Downloading documents into 'documents.path' = ./files-ctgov/
# - Created directory ./files-ctgov
# - Applying 'documents.regexp' to 40 missing documents
# - Creating subfolder for each trial
# - Downloading 40 missing documents
# = Newly saved 40 document(s) for 32 trial(s); 0 of such document(s) for 0 trial(s) already existed in ./files-ctgov
# = Imported or updated 32 trial(s)
# Updated history ("meta-info" in "collection_name")
# $n
# [1] 32
### CTGOV2 files are downloaded, using the default of documents.regexp
ctrLoadQueryIntoDb(
queryterm = "https://clinicaltrials.gov/search?cond=neuroblastoma&aggFilters=phase:1,results:with",
documents.path = "./files-ctgov2/",
con = db
)
# * Found search query from CTGOV2: cond=neuroblastoma&aggFilters=phase:1,results:with
# * Checking trials in CTGOV2, found 40 trials
# - Downloading in 1 batch(es) (max. 1000 trials each; estimate: 4 Mb total)
# - Load and convert batch 1...
# - Importing records into database...
# JSON file #: 1 / 1
# * Checking for documents...
# - Getting links to documents
# - Downloading documents into 'documents.path' = ./files-ctgov2/
# - Created directory ./files-ctgov2
# - Applying 'documents.regexp' to 43 missing documents
# - Creating subfolder for each trial
# - Downloading 43 missing documents
# = Newly saved 43 document(s) for 27 trial(s); 0 of such document(s) for 0
# trial(s) already existed in ./files-ctgov2
# = Imported or updated 40 trial(s)
# Updated history ("meta-info" in "collection_name")
# $n
# [1] 40
### ISRCTN files are downloaded, using the default of documents.regexp
ctrLoadQueryIntoDb(
queryterm = "https://www.isrctn.com/search?q=alzheimer",
documents.path = "./files-isrctn/",
con = db
)
# * Found search query from ISRCTN: q=alzheimer
# * Checking trials in ISRCTN, found 335 trials
# - Downloading trial file (estimate: 6 MB)
# - Converting to NDJSON (estimate: 2 s)...
# - Importing records into database...
# * Checking for documents...
# - Getting links to documents from data . correct with web pages . . . . . . . .
# - Downloading documents into 'documents.path' = ./files-isrctn/
# - Created directory ./files-isrctn
# - Applying 'documents.regexp' to 54 missing documents
# - Creating subfolder for each trial
# - Downloading 34 missing documents
# = Newly saved 34 document(s) for 16 trial(s); 0 of such document(s) for 0
# trial(s) already existed in ./files-isrctn
# = Imported or updated 335 trial(s)
# Updated history ("meta-info" in "collection_name")
# $n
# [1] 335
### CTIS files are downloaded, using a specific documents.regexp
ctrLoadQueryIntoDb(
queryterm = paste0(
"https://euclinicaltrials.eu/ctis-public/search#",
'searchCriteria={"containAny":"cancer","status":[8]}'),
documents.path = "./files-ctis/",
documents.regexp = "and icf",
con = db
)
# * Found search query from CTIS: searchCriteria={"containAny":"cancer","status":[8]}
# * Checking trials in CTIS, found 254 trials
# - Downloading and processing trial data... (estimate: 30 Mb)
# - Importing records into database...
# - Updating with additional data: .
# * Checking for documents . . .
# - Downloading documents into 'documents.path' = ./files-ctis/
# - Created directory ./files-ctis
# - Applying 'documents.regexp' to 3323 missing documents
# - Creating subfolder for each trial
# - Downloading 775 missing documents (excluding 4 documents with duplicate
# names, e.g. ./files-ctis/2024-512477-27-00/SbjctInfaICF - L1 SIS and ICF
# Main ICF German Redacted - 145056.PDF)
# - Resolving CDN and redirecting...
# = Newly saved 771 document(s) for 73 trial(s); 0 of such document(s) for
# 0 trial(s) already existed in ./files-ctis
# = Imported 254, updated 254 record(s) on 254 trial(s)
# Updated history ("meta-info" in "collection_name")
# $n
# [1] 254See also https://app.codecov.io/gh/rfhb/ctrdata/tree/master/R
# 2025-11-30
tinytest::test_all()
# test_ctrdata_duckdb_ctgov2.R.. 79 tests OK 57.1s
# test_ctrdata_function_activesubstance.R 4 tests OK 1.0s
# test_ctrdata_function_ctrgeneratequeries.R 10 tests OK 0.2s
# test_ctrdata_function_params.R 25 tests OK 1.2s
# test_ctrdata_function_various.R 79 tests OK 3.6s
# test_ctrdata_mongo_local_euctr.R 117 tests OK 1.2s
# test_ctrdata_mongo_remote_ro.R 4 tests OK 6.7s
# test_ctrdata_sqlite_ctgov.R... 46 tests OK 29.7s
# test_ctrdata_sqlite_ctis.R.... 94 tests OK 3.6s
# test_ctrdata_sqlite_isrctn.R.. 47 tests OK 18.0s
# test_euctr_error_sample.R..... 8 tests OK 0.2s
# All ok, 605 results (6m 49.3s)
covr::package_coverage(path = ".", type = "tests")
# ctrdata Coverage: 94.20%
# R/zzz.R: 55.56%
# R/ctrRerunQuery.R: 78.64%
# R/ctrShowOneTrial.R: 84.21%
# R/ctrLoadQueryIntoDbEuctr.R: 87.78%
# R/ctrGetQueryUrl.R: 89.18%
# R/ctrFindActiveSubstanceSynonyms.R: 89.36%
# R/dbGetFieldsIntoDf.R: 89.47%
# R/util_functions.R: 90.74%
# R/f_sponsorType.R: 92.00%
# R/ctrLoadQueryIntoDbCtgov2.R: 92.53%
# R/ctrLoadQueryIntoDbIsrctn.R: 95.70%
# R/dbFindFields.R: 95.88%
# R/f_primaryEndpointResults.R: 96.00%
# R/ctrLoadQueryIntoDb.R: 96.40%
# R/ctrLoadQueryIntoDbCtis.R: 96.53%
# R/dfMergeVariablesRelevel.R: 96.55%
# R/ctrGenerateQueries.R: 97.13%
# R/ctrOpenSearchPagesInBrowser.R: 97.50%
# R/dbFindIdsUniqueTrials.R: 98.78%
# R/f_externalLinks.R: 98.92%
# R/f_numTestArmsSubstances.R: 98.95%
# R/f_likelyPlatformTrial.R: 99.19%
# R/dbQueryHistory.R: 100.00%
# R/dfName2Value.R: 100.00%
# R/dfTrials2Long.R: 100.00%
# R/f_assignmentType.R: 100.00%
# R/f_controlType.R: 100.00%
# R/f_hasResults.R: 100.00%
# R/f_isMedIntervTrial.R: 100.00%
# R/f_isUniqueTrial.R: 100.00%
# R/f_numSites.R: 100.00%
# R/f_primaryEndpointDescription.R: 100.00%
# R/f_resultsDate.R: 100.00%
# R/f_sampleSize.R: 100.00%
# R/f_startDate.R: 100.00%
# R/f_statusRecruitment.R: 100.00%
# R/f_trialObjectives.R: 100.00%
# R/f_trialPhase.R: 100.00%
# R/f_trialPopulation.R: 100.00%
# R/f_trialTitle.R: 100.00%See project outline https://github.com/users/rfhb/projects/1
Authentication, expected to be required by CTGOV2; specifications not yet known (work not yet started).
Explore further registers (exploration is continually ongoing; added value, terms and conditions for programmatic access vary; no clear roadmap is established yet).
Data providers and curators of the clinical trial registers.
Please review and respect their copyrights and terms and conditions, see
ctrOpenSearchPagesInBrowser(copyright = TRUE).
Package ctrdata has been made possible building on
the work done for R, dplyr, duckdb, htmlwidgets,
httr2, jqr, jsonlite, lubridate, mongolite, nodbi, readr. rlang, RPostgres, RSQLite, stringdist and
stringi and tidyr, V8, xml2.
Information in trial registers may not be fully correct; see for example this publication on CTGOV.
A warning may be issued and a record not imported if the complexity of the XML content is too high for processing. The issue can be resolved by increasing in the operating system the stack size available to R, see: https://github.com/rfhb/ctrdata/issues/22
Please file issues and bugs here.
Check out any relevant closed issues, e.g. on C stack usage too close to the limit and on a SSL certificate problem: unable to get local issuer certificate.